Intelligence and automation for newsrooms
On April 18 and 19, we had the opportunity to attend an event sponsored by the Mozilla Foundation and the Knight Foundation: The Open News 2016 Code Convening in Austin, TX. This initiative consists of creating Open Source Software solutions for journalism teams. The teams were selected to develop their projects over the Internet, and we were the first international team to participate in the dynamic. It is worth noting that the event participants came from different backgrounds, some from National Public Radios (NPR), The New York Times, investigative journalists, The Marshall Project—which covers the US Justice System and won a Pulitzer during the event—independent journalists, among others. All in a dynamic similar to a hackathon where collaboration and intensive work over two days materialized in advances of an open source project that will help automate newsrooms in the United States and surely Mexico.
One thing I personally liked is that the event is focused on testing a new way to make hackathons more effective, with projects that have already started and need feedback to continue their development. At the same time, the event was like a mini-conference because there was time to share challenges in: journalism, data analysis, and technology management in news portals. Sharing experiences openly about best practices and especially solutions to common problems was one of the most enriching experiences for all teams.
The projects notably focused on two thematic paths: Collection and use of information, and automation of reports with metrics for portals through bots. Neil, an independent programmer who does not yet work on any journalism team, made an automatic Podcast generator from text. It’s like programming a bot that turns news into audio. Automation and reliable use of information was the guiding principle for all teams.
Design by Sandra Barrón
Design by Sandra Barrón
The Cívica Digital team: Sandra Barrón as product designer, Miguel Morán a.k.a. Mikesaurio, and myself as software developers attended with the proposal of La Refinadora. We started this project with the organization México Abierto and are interested in continuing to develop it collaboratively. La Refinadora is a project that helps you validate datasets according to a standard format. This means that if you have information in an open format, like a CSV, you can validate: that dates are according to the ISO-8601 standard, that a CSV meets its format, you could even validate encoding, among other validations and information formats.
The importance of La Refinadora is that we need help to improve the quality of datasets. A couple of years ago, we perhaps had a dilemma about how to help create an Open Data strategy, how to help publish that data and have the community use it. But technically, at this moment, it is relevant to help make information homogeneous, to conform to standards, and to be able to do it massively and automatically in any language. There are even authors like McCallum and Gleason in ‘Business Models for the Data Economy’ (O’Reilly Media, 2012) who assert that one of the economic niches where value can be created with data is Filtering and Refining (data) so that clients of our information can trust it. Thus, data analysts, businesses, and journalists can use information from Open Data sources with confidence. And for those who do not trust the source, it would serve so they can verify it.
La Refinadora was conceived with these principles, and that’s why when it was first designed, the possibility of using containers with Docker was considered, to create isolated environments for running scripts in different languages. We have detected several languages, depending on the team working with the information. However, if you need to use Clojure, then use a Docker image with the JVM. If you need to run your script with Python, then use an image with a configured Python interpreter and all its utilities or dependencies configurable. It should be easy to offer a diverse execution environment for entities that need diversity and at the same time be standard; the possibilities with containers expand and are increasingly accessible.
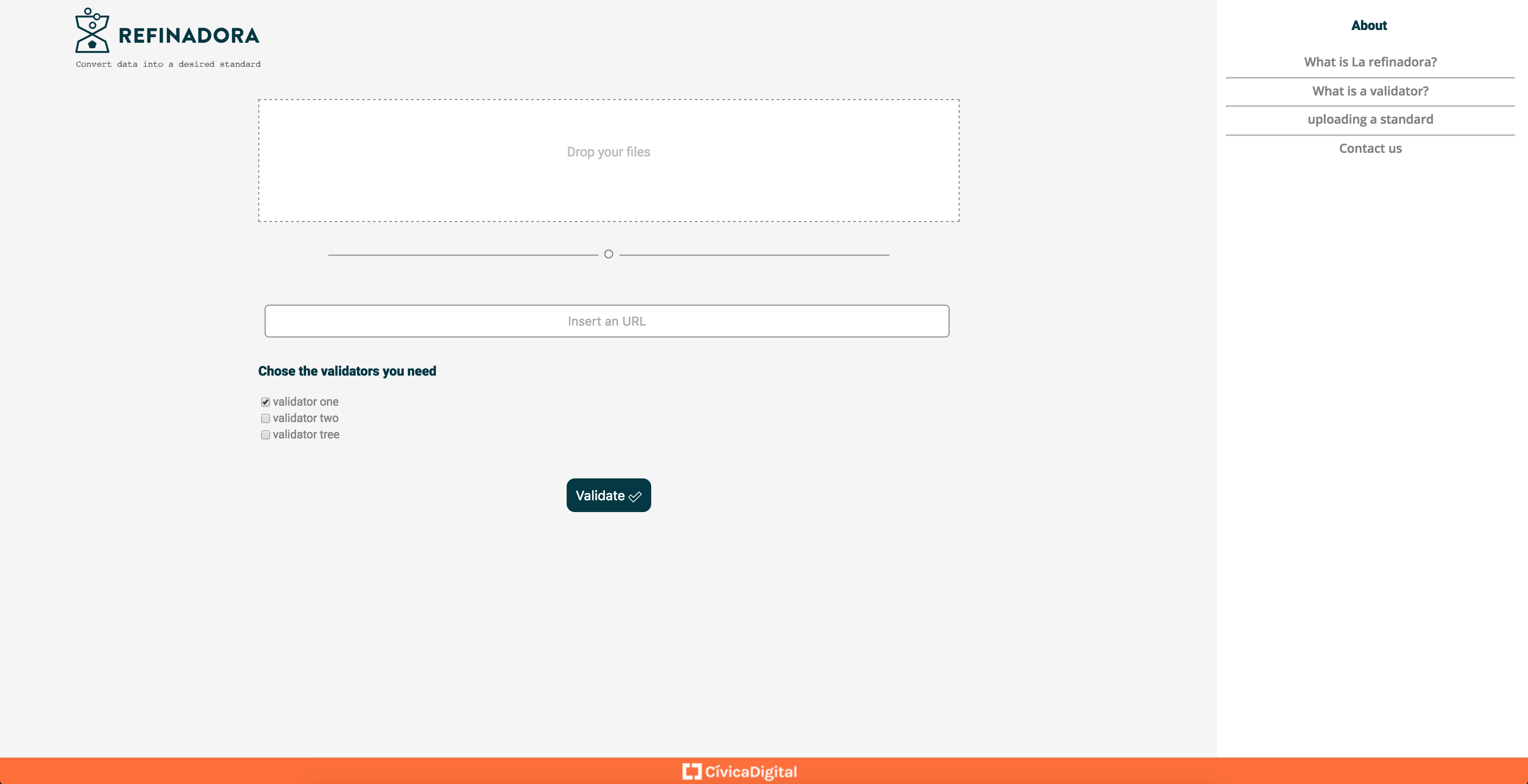
The new interface we designed for La Refinadora and implemented by Mikesaurio
The new interface we designed for La Refinadora and implemented by Mikesaurio and Sandra
The interface, as we detected with users, must be plural and available for different user profiles, both technical in programming and not so much. That’s why, in addition to an interface for ingesting by Data Catalogs in DCAT format, which is already used by default in the European Union and Mexico, we now created an interface to upload files via web easily. Now you can drag your files from a folder to the web interface and select the validators. With this, we improve accessibility for non-automated tasks and users with less technical profiles.

At the demo presentation
At the demo presentation
The experience was enriching because we worked with journalists and IT professionals on this topic, and it was incredible to meet one of the creators of Tabula, which already has a long history among those who started liberating data from PDFs. However, it is clear to us that these types of specialized meetings help pave the way with new tools for information processing, which can serve tasks such as: Data Analysis, Data Journalism, and Data Visualization. This remains a very specialized task, and we must continue developing projects that can help with this important task.
I invite you to check out the La Refinadora repository at github.com/civica-digital/la-refinadora. For now, we have also created new documentation in English so that developers worldwide can help us improve the first design. If you know Python, Docker, and are interested in this Open Data tool, we invite you to write to us on Github, and if you go to Pycon-US 2016, we’ll see you at the Sprints.
Noé Domínguez(@poguez)
Cover photo by Sandra Barrón [Post originally written for the blog of Civica.digital]